AI Safety research and consulting
At Tattle we focus on investigation and mitigation of unanticipated outcomes in AI tools. Through collaborative/ cross-disciplinary approaches we identify contextual and emergent risks in multilingual/multicultural settings, especially in India. We create datasets, propose design recommendations and develop customizable tools to address emerging risks. We also produce original research and publications based on our AI safety work.
Types of services
- Manual and automated evaluations of AI applications
- Creating datasets, including benchmarks, for safety and socio-cultural evaluations
- Developing bespoke AI guardrails
Methodology
Manual Evaluation
Tattle has developed a four-step process for conducting human evaluations of LLM systems. This is an iterative research process that involves conducting repeated sequences of the following four steps on each dataset:- Sampling data from human to LLM chats/interactions.
- Annotating sampled data by paying attention to unique characteristics of each use case.
- Expanding sample through targeted keyword searches.
- Analysing annotations to identify categories of risks and errors emerging from the AI tool and prioritize safety issues.
Technology Development
Tattle has been working on building open source datasets and software to tackle India specific challenges to online harms. Through our work on Feluda and Uli, we have built expertise in building solutions that operate on multimodal and multilingual data and are suited for the Indian context. We bring these learnings and experience to AI safety. Following our manual evaluation methodology, we co-create solutions in close collaboration with our partners.Case studies
ML Commons Benchmark Dataset

In 2024, Tattle built a dataset of prompts in Hindi for ML Common’s safety benchmark. We created 2000 prompts in Hindi on two hazard categories - hate and sex-related crimes. Following Uli’s participatory approach, these prompts were created by an expert group, consisting of individuals with expertise in journalism, social work, feminist advocacy, gender studies, fact-checking, political campaigning, education, psychology, and research.
Guardrails for Kaapi Project
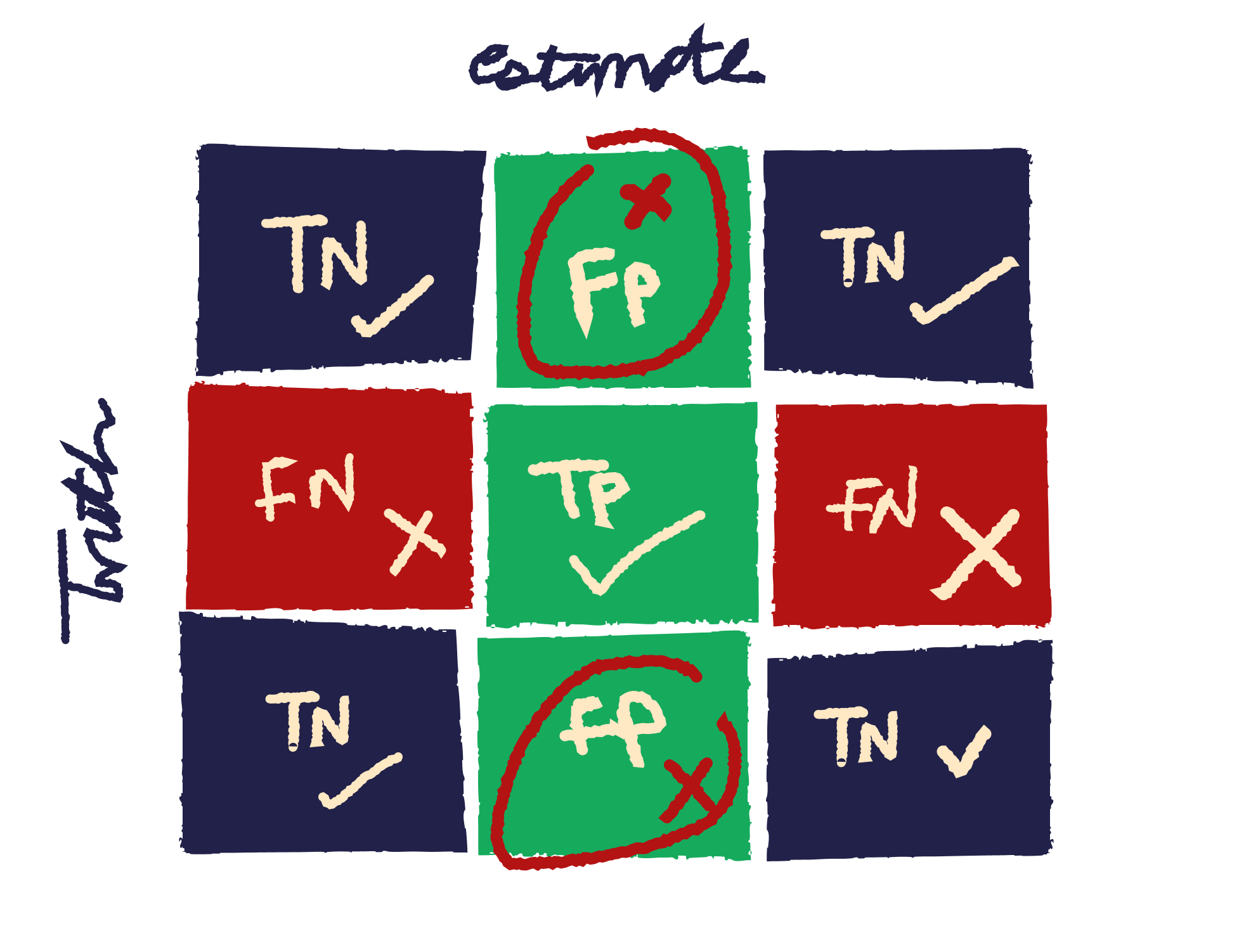
We participated in Tech4Dev’s AI cohort program and helped them conceptualize and build safety guardrails for the participating NGOs. The first step in this process was to conduct manual evaluations of sample datasets from NGO AI use cases to determine critical risks and develop relevant guardrails. This led to the creation of the Kaapi Guardrails, an API-first microservice for enforcing safety constraints in user-LLM interactions. This is available as an open source project for the community to self host and use in their AI solutions.
Stress Testing IIT Madras Chatbot

We were contracted by IIT Madras’ Online Bsc program to conduct a preliminary stress testing/red-teaming of their AI bot that answers questions for prospective applicants. As a comprehensive evaluation, we reviewed their gold dataset of question-answer pairs, evaluated input-output pairs from the live data and did some red teaming.. We provided recommendations on implementation that might reduce misuse. We provided a report highlighting strengths and weaknesses of the bot, recommendations for fine tuning and safety improvements, and shared a customizable slur detection module guardrail with support for Hindi, English and Tamil.
Publications
- Analysis of Indic Language Capabilities in LLMs
- Report for MLCommons: AI safety benchmark Datasets in Hindi
- AILuminate: Introducing v1.0 of the AI Risk and Reliability Benchmark from MLCommons:
- Participation in AI: Notes from the trenches
- Towards Functional Safety in AI in the Social Sector
- Manual Evaluations of AI in the Social Sector
- What is AI safety?