A Brief Intro To GPT-3
Tags:

On July 11, 2020 Open AI released its GPT-3 API to a few individuals.What developers were able to build with the API with fairly few lines of code dazzled them.

Developers tweeted about it. Other technologists (who didn’t have access to the API) were also dazzled by it. The chorus got bigger and the technology came to broader attention.

But the technology is hardly new!

Which raises the important question:
What then is different?
GPT-3 is a language model that is trained on a LOT more data. GPT-2, the predecessor to GPT-3, is trained on 40 GB of Internet Text. GPT-3 is trained on 45 TB of Internet text.
To give a sense of scale- if the black dot is what GPT-2 trained on, the orange sphere is what GPT-3 trained on (actually slightly more).
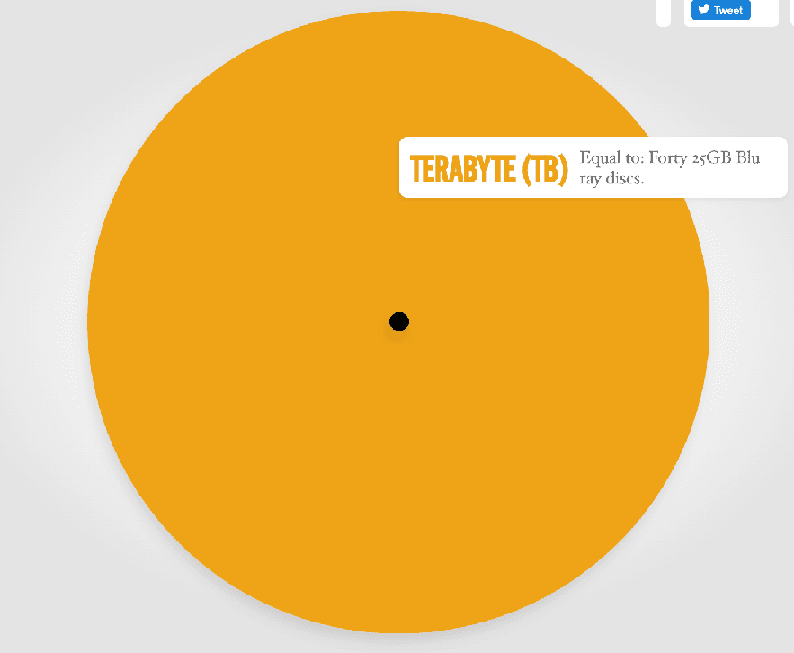
Visualization by RedCentric
Did We Also Say Something about a Language Model?

Language modeling is the task of assigning a probability to sentences in a language.
There is some technical complexity to how language models are implemented but we can leave that out for this introduction.

In effect this is what happens:
You throw a lot of text at the model, and from that text the model infers how probable a word or sequence of words are given a sequence of words preceding it.


What is This Whole Talk of Priming?
GPT-3 is trained on public conversations on the world wide web. People have all sorts of conversations online- we write about wide ranging issues, we debate, discuss product reviews, post questions on fora like Stack Overflow and Quora. The range of conversation online mirrors the range of our daily conversations. A sentence or phrase only gets meaning from its context. For example, the word 'Date' would be used very differently in a group of botanists (as a fruit), in a Microsoft Excel debugging forum and in a relationship advice forum.

GPT-3 adopts "in-context learning”. The developers feed the model a prompt or a few demonstrations of the task. This narrows down the 'subspace' from which the model predicts its outputs. This ensures that the outputs are tweaked to be relevant to the context (of the prompt).
But What Is All This Talk of Generating Code???
Take this use case where the person was able to generate elements used on a website in plain English. An extreme extension of this application would be a person describing the kind of website they want in English and an application built on GPT-3 generating the website for you. You could have a customized website without needing to code.

To implement this feature, the developer primed the model with two example, where they provided English statements and a corresponding code equivalent to it. One thing to remember is that there are a lot of code snippets online (on forum such as Stack Overflow, coding blog posts, and Github repositories). So GPT-3 possibly had a lot of coding example to learn from.
Once the model was 'primed' on code snippets, it responded to input English sentences with coding statements as output.

So is GPT-3 Going to Change The World As We Know It?
At this stage it is hard to predict all the ways in which GPT-3 and its offsprings will be used. Like all machine learning models, it fails in unpredictable ways. It is also displaying known issues of bias in ML. We will definitely see a lot more generated text from GPT-3, which doesn't bode well for people grading student essays or for people tracing misinformation. But as for other creative use cases, "it is too early to say" if they will meet consumer product standards.
Thats All For Now.

This blog doesn't have a comments section, so if you'd like to discuss more find us on Twitter.Or email. Or Slack.
Attribution
All the images and GIFs, except for the first one, were found on Google Images.