Archiving data from Sharechat, a made-in-India social network
Published on Mon May 25 2020Tags:
Online misinformation in India goes beyond "global" networking platforms like Whatsapp, Twitter or Facebook. Our ongoing archiving of content circulated on Indian chat apps and social networks brought us to Sharechat, a popular social network designed for sharing and consuming content exclusively in Indian languages. Sharechat had over 60 million monthly active users as of April 2019, and is a rich source of publicly accessible multilingual Indian content.
Much of this content is similar to what is circulated on Whatsapp groups, and like Whatsapp, Sharechat also has instances of misinformation being spread on its platform. These similarities, as well as the desire to understand how information and misinformation spread on vernacular social networks, convinced us to include Sharechat data in the Tattle archive.
Targeted scraping
Scraping Sharechat involves carefully curating tags, media types and metadata fields since we only want to archive relevant content. Temporal metadata particularly impacts the archival process, by enabling us to scrape batches of freshly posted content and study their life cycle on the platform.
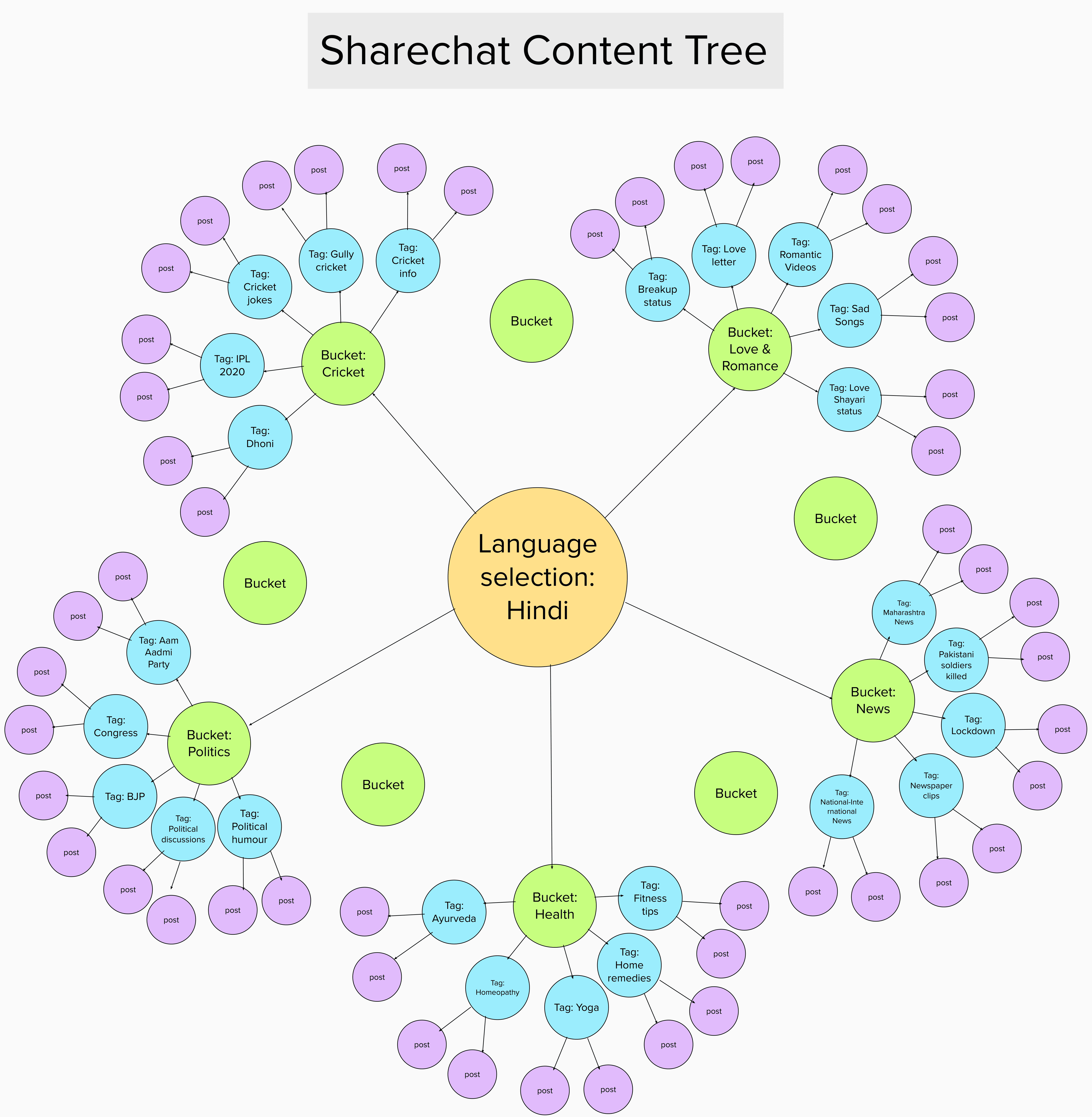
Finding all of this information is fairly straightforward. Sharechat's content structure could be described like this: Each language contains broad content buckets > each bucket contains narrower content tags > each tag contains posts (images, videos, text, audio, GIFs) that have been uploaded with that tag.
The posts are accompanied by metadata such as captions, timestamps, views, likes, external shares, reposts and comments.
There are several ways to discover content on Sharechat, but let's look at an example that follows the content structure above:
- A user selects Hindi as her language on the homepage and then navigates to the 'News' bucket inside the Explore section.
- From the list of tags displayed within the bucket, she selects a tag named 'My Area News'.
- This takes her to the tag page where she can scroll through the posts, which are further organised by content type.
Demystifying content tags
Tags are an intriguing feature of the platform. Each tag has a 'trending' section, the logic behind which is not so straightforward. Posts that appear in the trending section are neither sorted by virality, nor by recency, nor by any obvious characteristics of the accounts that post them. We did not find any significant difference in the content when we visited the same trending section before and after logging in as a user. However, each tag also has a 'fresh' section whose posts are sorted chronologically. These sections enable scraping with temporal parameters.
It's worth noting that tags are seeded by the platform itself and indicate what type of content is encouraged on the platform. We found instances where 'empty' tags related to news stories appeared within content buckets and subsequently filled up with posts, indicating that the platform-created tags had facilitated topical content sharing.
Some tags, such as those within the 'Coronavirus' bucket, have a dramatic tone, emojis and/or emphasis markers in the tag name. Others, such as those in the 'News' bucket, are more concise and neutral-looking. And while some tags like 'Worldwide News' are permanent, others like 'Pakistani Soldiers Killed' emerge in response to breaking news and 'die' a few days later.
These examples may give the impression that Sharechat is filled with newsy content. In reality, newsy content is a small part of the Sharechat universe. Buckets dedicated to funny videos and jokes, romantic poetry, song and dance, sports, food, motivational quotes and 'good morning' messages of the Whatsapp variety are a big part of the platform. Astrology has a bucket of its own, as does Health - which contains Ayurveda and Homeopathy tags that are arguably also worth archiving.
The misinformation challenge
Archiving relevant information from Sharechat is a two-step process. The first step is scraping content from specific tags. (See our Sharechat scraper repo on GitHub) The second step is identifying potential misinformation in the content.
Sharechat appears to be aware of misinformation on the platform. Tags with names like 'Beware of Fake News' can be spotted here and there, but these are not very useful as many users appear to be piggybacking on the tag's visibility to post unrelated content.
The multimodalities and multilinguality of the content promise to make the second step challenging. A variety of approaches, from simple keyword filters to multimodal Machine Learning models that can handle text, image, video and audio, will need to be experimented with.